
|
|
During the Double-Take Availability installation, you identified the amount of disk space that can be used for Double-Take Availability queuing. Queuing to disk allows Double-Take Availability to accommodate high volume processing that might otherwise fill up system memory. For example, on the source, this may occur if the data is changing faster than it can be transmitted to the target, or on the target, a locked file might cause processing to backup.
The following diagram will help you understand how queuing works. Each numbered step is described after the diagram.
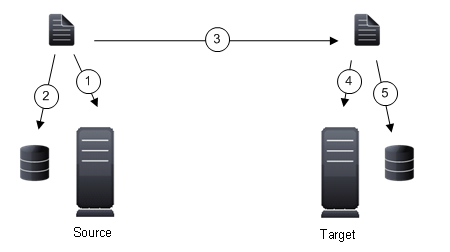
When the allocated amount of system memory is full, new changed data bypasses the full system memory and is queued directly to disk. Data queued to disk is written to a transaction log. Each transaction log can store 5 MB worth of data. Once the log file limit has been reached, a new transaction log is created. The logs can be distinguished by the file name which includes the target IP address, the Double-Take Availability port, the connection ID, and an incrementing sequence number.
You may notice transaction log files that are not the defined size limit. This is because data operations are not split. For example, if a transaction log has 10 KB left until the limit and the next operation to be applied to that file is greater than 10 KB, a new transaction log file will be created to store that next operation. Also, if one operation is larger than the defined size limit, the entire operation will be written to one transaction log.
Like the source, system memory on the target contains the oldest data so when data is applied to the target, Double-Take Availability pulls the data from system memory. Double-Take Availability automatically moves operations from the oldest transaction log file to system memory. As a transaction log is depleted, it is deleted. When all of the transaction log files are deleted, data is again written directly to system memory (step 4).
 Related Topics
Related Topics